
Data Integration Services
Get Single Version of Truth
Data Integration consulting and Data Integration services across diverse data sources like social media, unstructured data (audio, video, files, emails), large data logs (call records, web logs), big data including IoT
Real time data integration services & analytics
Performance tuning for faster ETL processes, to the tune of 10x efficiency improvement
ETL services supported by appropriate Data Governance, Data Quality and Master Data Management that ensure clear, relevant and accurate insights
Domain specific data modelling capabilities leading to more contextual insights
Choice of right technology stack for Data Warehouse, as well as optimal DW sizing
The data are stored in our high-speed and secure data warehouse that is protected 24/7.
We deliver smart ETL scripts factoring complex and comprehensive business rules.
Best-in-class Data integration capabilities to cater to Big Data.
Data Integration
Get Single Version of Truth
Data Integration consulting and Data Integration services across diverse data sources like social media, unstructured data (audio, video, files, emails), large data logs (call records, web logs), big data including IoT
Real time data integration services & analytics
Performance tuning for faster ETL processes, to the tune of 10x efficiency improvement
ETL services supported by appropriate Data Governance, Data Quality and Master Data Management that ensure clear, relevant and accurate insights
Domain specific data modelling capabilities leading to more contextual insights
Choice of right technology stack for Data Warehouse, as well as optimal DW sizing
The data are stored in our high-speed and secure data warehouse that is protected 24/7.
We deliver smart ETL scripts factoring complex and comprehensive business rules.
Best-in-class Data integration capabilities to cater to Big Data.
Expertise across Technology Stacks
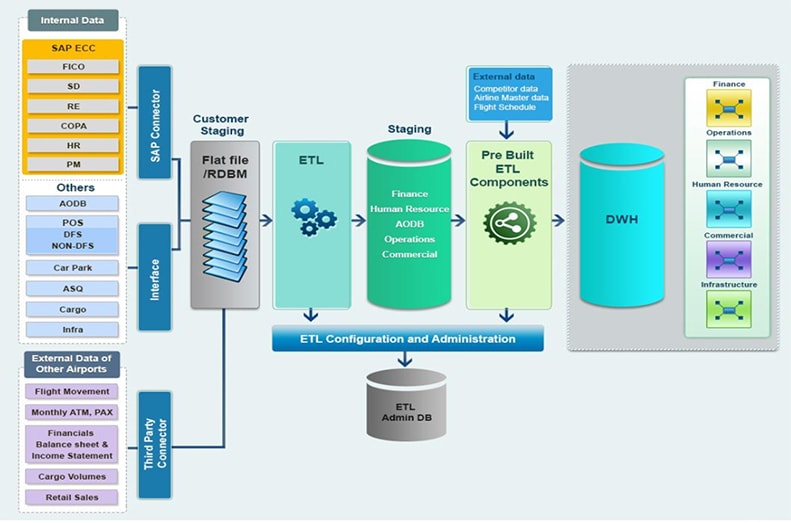
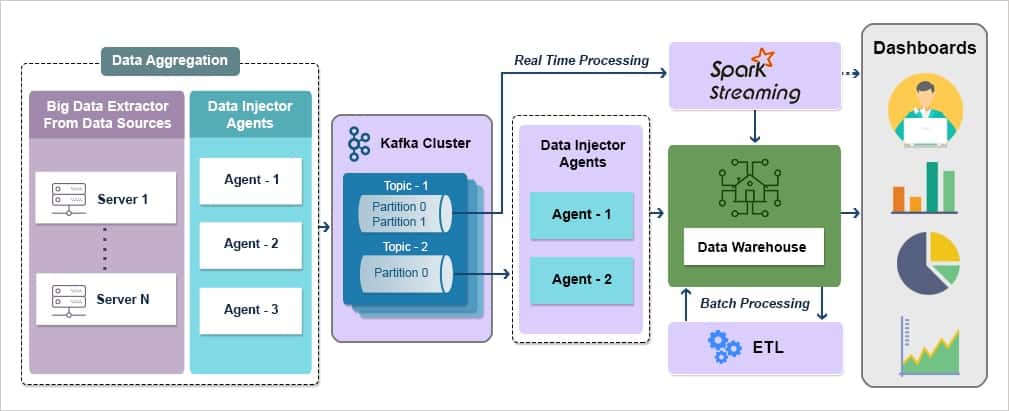
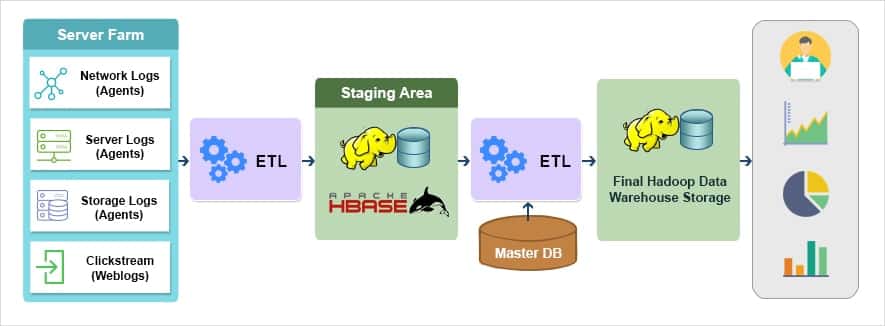
GrayMatter has successfully solved complex data integration problems for customers across the globe. GrayMatter has expert teams for data integration services dedicated to each of the major data integration implementation stacks like SAP BODS, SAP BW, Pentaho Kettle, MS SSIS, Pentaho Data Integration API, Informatica, Power BI Data Integration consulting services and Talend. GrayMatter also has exceptional competencies in Master Data Management, Data Governance and Data Quality which support and augment the objective of Data Integration Consulting Services. Equipped with all these competencies and rich experience of over 2 million person hours, GrayMatter adopts an end-to-end solution approach consisting of data integration consulting services followed by seamless execution.








Complete Data Integration Services & Solutions
Bring all your raw data together in real-time and from all silos, for secure, real-time insights.
Today, most entreprises find themselves in a position of producing and storing ample amounts of data every day. As in abundance, it becomes quite difficult to tap onto the potential of the meaningful information out of this amount. With Gray Matter’s Data Integration services, you no longer need to struggle with the complex ETL processes anymore.
No more data preparation to set up complex ETL processes.
Our ETL services access your data wherever it is stored, in whatever format, and brings along information being used by your enterprise. We enable performance tuning for faster ETL processes to the extent of 10x. Not only this, but we also provide pre-built industry-specific analytics solutions, and hence the complete enterprise data integration piece does not need any from-the-scratch effort.

Our ETL service makes sure to maintain end-to-end security for your data. The data are stored in our high-speed and secure data warehouse that is protected 24/7 and is the right choice of the stack for Data Warehouse. What matters to us above all, is, our customer’s most sensitive data and its security and we are totally committed toward this.

What if there is a sudden change in your data?
No worries, our Data Integration services make sure you never miss an important event and handles it, in no-time, already! We manage the data schema changes and restructure for optimization purposes. We understand your concerns and convert the data in the way you want it to be by enabling the automatic mapping of integrations. We can also customize the mapping for you in case you need to take full control over it.
Our data integration consulting and data integration services save your time, efforts, and money, without compromising the flexibility and scalability required for data integration. GrayMatter is a proven data integration service provider in the USA as well as the rest of the world, with successful implementations for global customers






What Exactly is Data Integration?
No worries, our Data Integration services make sure you never miss an important event and handles it, in no-time, already! We manage the data schema changes and restructure for optimization purposes. We understand your concerns and convert the data in the way you want it to be by enabling the automatic mapping of integrations. We can also customize the mapping for you in case you need to take full control over it.


Why Data Integration is Important
Many companies will be focusing on data-driven business this year. By reducing technical complexity and creating a single point of access to all of your data, you can achieve a better understanding of your data and the reality it depicts.
Types of Data Integration Techniques
Data integration aims at providing an integrated and consistent view of data coming from internal and external data sources. This is achieved in using one of the three different data integration techniques, depending on the heterogeneity, complexity, and volume of data sources involved.
Data Consolidation
As the name suggests, data consolidation is the process of consolidating or combining data from different data sources to create a centralized data repository or data store. This unified data store is then used for various purposes, such as reporting and data analysis. In addition, it can also perform as a data source for downstream applications.
One of the key factors that differentiate data consolidation from other data integration techniques is data latency. Data latency is defined as the amount of time it takes to retrieve data from data sources to transfer to the data store. The shorter the latency period, the fresher data is available in the data store for BI and analysis.
There is usually some level of latency between the time updates occur to the data stored in source systems and the time those updates reflect in the data warehouse or data source. Depending on the data integration technologies used and the specific needs of the business, this latency can be of a few seconds, hours, or more. However, with advancements in data integration technologies, it is possible to consolidate data and transfer changes to the destination in near real-time or real-time.

Data Federation
Data federation is a data integration technique that is used to consolidate data and simplify access for consuming users and front-end applications. In data federation, distributed data with different data models is integrated into a virtual database that features a unified data model.
There is no physical data integration happening behind a federated virtual database. Instead, data abstraction is done to create a uniform user interface for data access and retrieval. As a result, whenever a user or an application queries the federated virtual database, the query is decomposed and sent to the relevant underlying data source. In other words, the data is served on an on-demand basis in data federation, unlike data consolidated in which data is integrated to build a centralized data store.
Data Propagation
Data propagation is another technique for data integration in which data from an enterprise data warehouse is transferred to different data marts after the required transformations. Since the data continues to update in the data warehouse, changes are propagated to the source data mart in a synchronous or asynchronous manner. The two common technologies used for data propagation include enterprise application integration (EAI) and enterprise data replication (EDR). These are discussed below.

Data Integration Challenges
A variety of tools, platforms, and sources can be used to ingest and store data. Getting everything into one place can be a major challenge. What’s more, new data sources are introduced all the time. This means scale and schema flexibility are paramount.
Aggregated data is often inferior to raw data when deriving analyses and insights to make data-driven decisions. However, your raw data may be in different, barely-accessible formats.
The opportunities missed from not having the right information at the right time can lead to money left on the table and inaccurate predictions.
CUSTOMER SPEAK

“Great dashboard to understand the airport environment at a glance. Comprehensive detection of changes in the business and ability to support and make decisions. The integration of all your airport data into one should be available for every airport globally.”
