
Implementing Data Quality for Enterprise Data Warehouse Solutions
Data quality implementation is important in the context of Data Warehouse and Business Intelligence. An Enterprise Data Warehouse Solutions is an integral part of those enterprises which want to have clear business insights from customer and operational data. It has been observed that fundamental problems arise in populating a warehouse with quality data from various multiple sources systems.
GrayMatter’s experts have ensured data quality for enterprise data warehouse solutions for global customers using varied technology stacks. Let us see the below DWBI Architecture, one without Data Quality implemented and other with Data quality implemented.
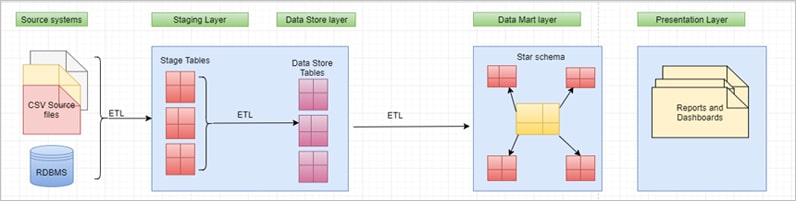
DWBI Architecture without Data quality implemented
Data from source is extracted as it is and loaded into stage tables (Landing layer) without any transformation using ETL. Post which data from Stage tables will be extracted and loaded to Data Store layer (Persistent layer). As a final process, data from DS layer will be extracted, transformed and loaded into Data Marts/DW.
The problem with this approach is, there are no Data quality checks implemented in the source data and because of which Enterprise Data Warehouse Solutions might get populated with poor quality data which could lead into wrong analysis and faulty decisions.
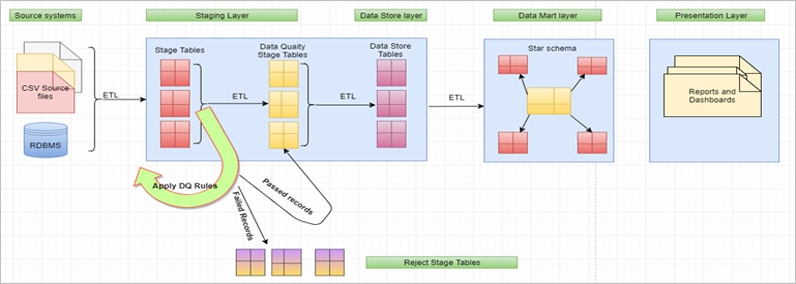
DWBI Architecture with Data quality implemented
Once the data is loaded into stage tables, ETL will trigger Data quality check process on the stage table data. For each stage table, ETL picks up the DQ Rules (Query) defined in the DQ meta data table and executes to identify which all are the records violating the rules. Accordingly, this process will mark/update those bad quality records with the respective DQ rule IDs. Single record can be failed due to multiple rules and those DQ rule IDs will be updated against those records.
Once the DQ process is completed, there is another ETL/Process that picks up all the bad quality records from Stage table and moves to Reject tables. These records can be identified by applying a filter “.DQ_Rule_ID is NOT NULL”. Same way another ETL/process that picks up good quality data from Stage to Data Quality stage and from there to Data Store and DW/Data Marts.
As an illustration of Data Warehouse Implementation, following section details how this can be achieved using Pentaho Data Integration (PDI).
Technical Implementation of Data Quality using Pentaho Data Integration (PDI)
For this implementation using Pentaho Data Integration, we need to have some user defined meta data tables as below:
- ETL_RT_DAILY_JOBS – This table will have the information such as ETL Job name, Module Name (Same as module name) and some other audit information that gets populated when the ETL job is triggered
- ETL_DQ_MASTER – This table will have all the Data Quality – Enterprise Data Warehouse Solutions rules for each Stage table. DQ rules are maintained in the form of Database query as shown below. We can add ‘n’ number of DQ rules for each source entity (Table)
- Note
- Stage table is a temporary table that gets loaded as it is from Source. Hence it will hold the same data as source with no change
- Refer Fig-3 for the ETL_DQ_MASTER table structure and data. We can have any kind of rule such as query for De dupe check (Query to identify Duplicate records), PK column null check, Foreign Key constraint violation, date formats etc.
1. De-Dupe Check
Let us create an ETL job as below. Also it is very important that you need to define the De-Dupe check query in the ETL_DQ_MASTER table for the respective stage table. Also, we will have to add a column IS_DUPLICATE to the stage table which will have values 0 or 1. 1 indicates Duplicate records.

“GENERIC SQL QUERY” job is the step that will call a job as below which is used to identify the duplicate records in the stage tables based on the rule defined in the DQ rule Meta data tables and RULE Type such as “De_Dupe_Check”, “Row_Level_DQ_Reject” etc.

Below are the steps used in “Apply De Dupe Rule” transformation.
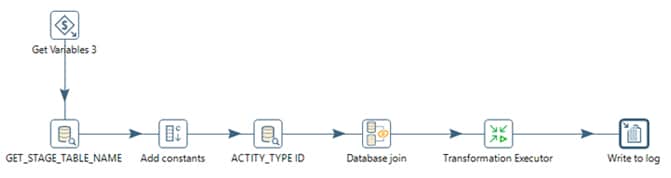
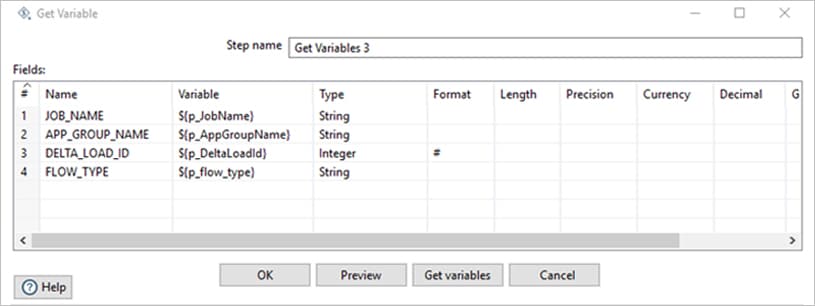
Get variables step is being used to get the variable values for ETL Job Name, App Group Name (Same as module name) etc.
Then we will do a look up to ETL_RT_DAILY_JOBS to get the stage table name
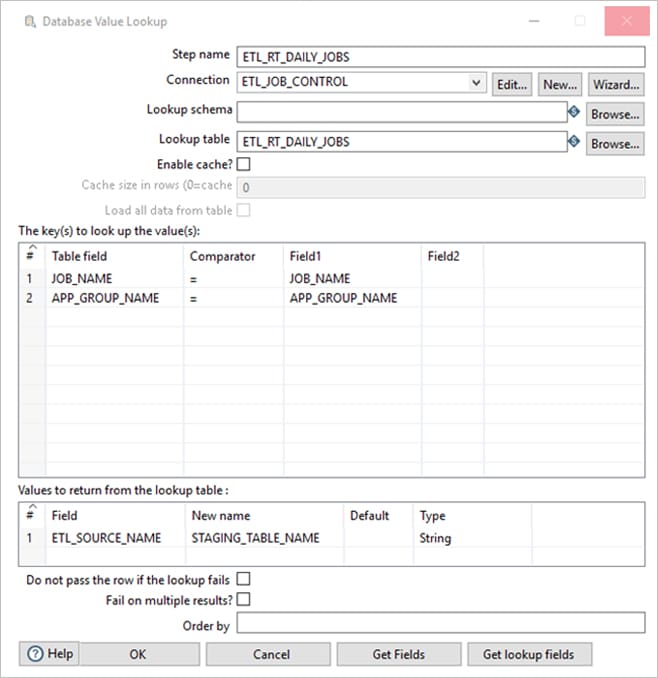
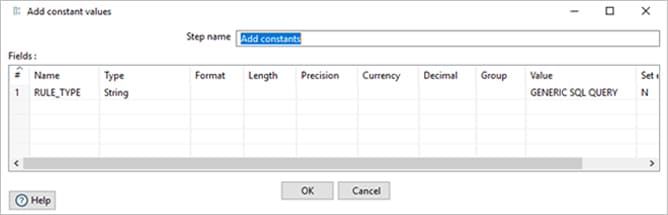
Then the stage table name, DQ rule type is being passed to ETL_DQ_MASTER to get the DQ Rule ID, Rule for each stage table
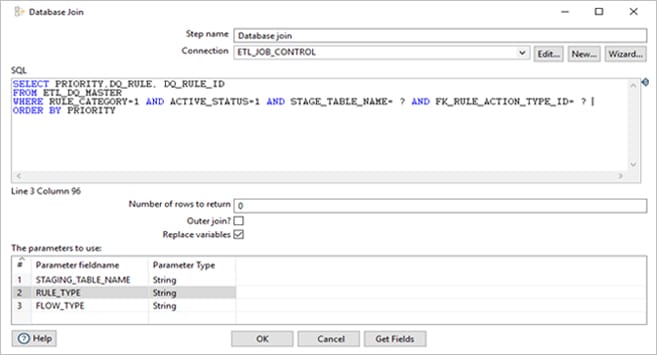
Once the stage table name, DQ Rule ID, DQ rule is obtained, a transformation is being call with below values are parameters.
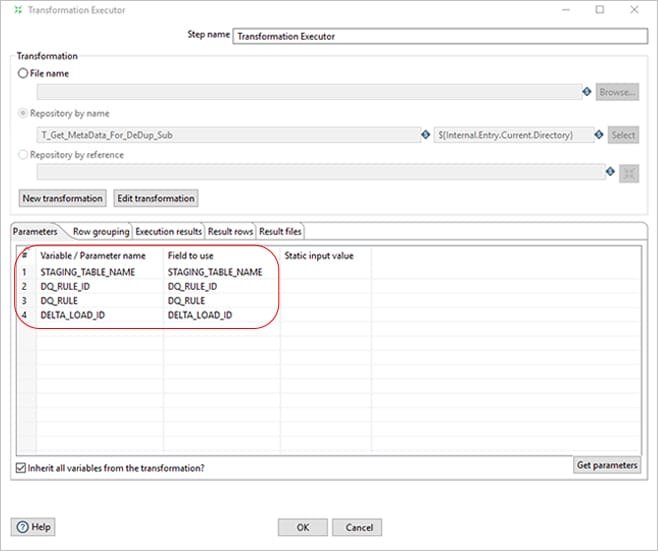
In this transformation, we will get all the variables using “Get Variables” and an “Execute SQL Script” step that executes the DQ rule (Query defined in ETL_DQ_MASTER) as shown below. The highlighted is the way of passing variable and the parameter is the DQ_RULE field which is the query defined in ETL_DQ_MASTER.

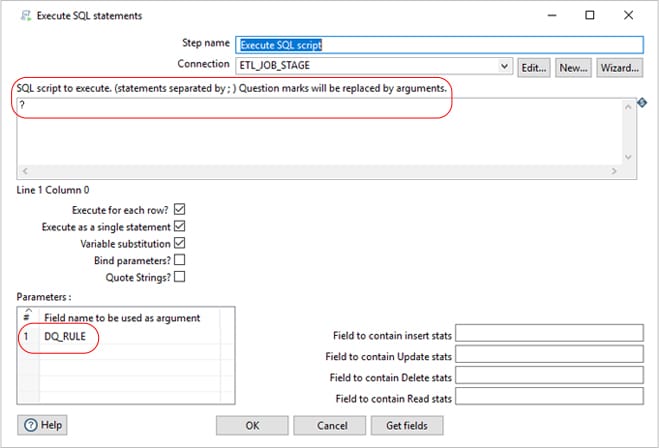
Once this Job “GENERIC SQL QUERY” is completed, all the duplicate records in the respective stage table will be marked as IS_DUPLICATE – 1. The records with value IS_DUPLICATE -0 will be good quality records for further processing
2. Row Level DQ quality check implementation
Once the De-Dupe job is completed, another job “Apply Data Rejection Rules” being called with steps as given below.

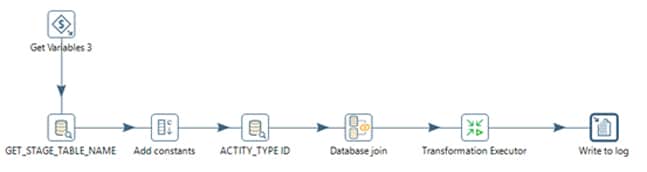
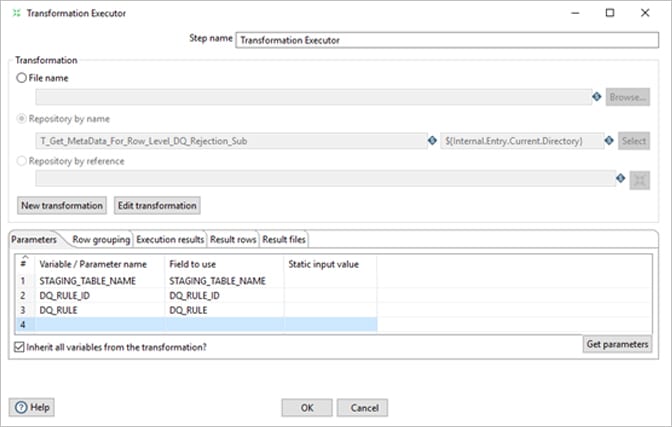
Here for this Rule type, unlike De-Dup DQ rule column value fro ETL_DQ_MASTER for each stage table will be appended with the Update statement of below “Execute SQL Script”.
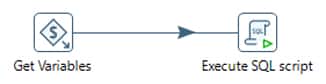
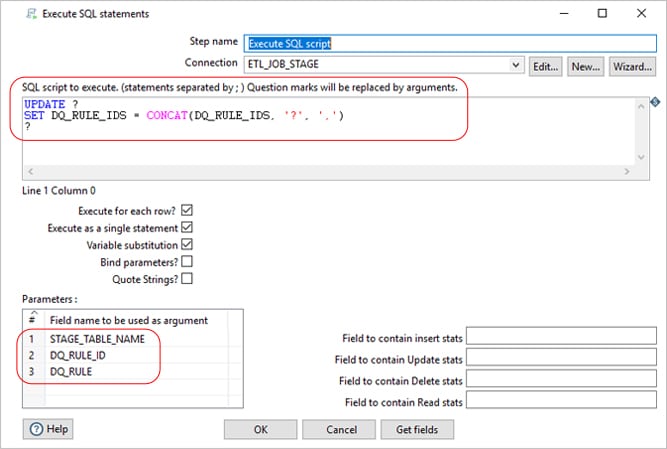
Once the Job is completed, all the stage table records which are violating the rules will be marked with respective DQ rules (Append the DQ rule IDs if single record is breaking multiple rules)

