

In this blog I intend to explain why and how MetaData Ingestion feature can be implemented to parameterize ETL using Pentaho Data Integration (Kettle). The blog also covers how this approach is beneficial from a project development stand point.
Illustrative Scenario
Let us assume a use case of a DW/BI project where customer is providing source data as large number of CSV files with the required format which includes file name format, delimiter, column headers etc. As per the scope of the project, source data needs to be integrated to a Data warehouse which will in-turn become the source for Analytics Dashboards and Reports.
Indicative Architecture is given below
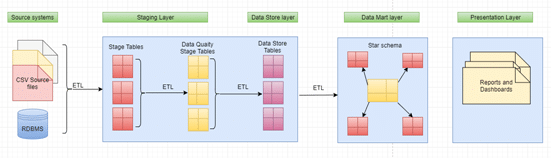
As per the architecture, source data needs to be extracted and loaded to the stage tables (Temporary layer) daily. Subsequently data is moved from stage to Data quality stage after data cleansing is done and from Data quality stage to Data store which is a persistent layer. Data store is same as source data and the main difference is that it would consist of cleansed data. Then finally this data needs to be integrated from Data store to Data Warehouse (Dimensions, Facts and Aggregates) for Dashboards and Reports to query and get data from.
Problem Statement
The number of source files to be integrated to Data Warehouse across the modules is very high including history and incremental data. Creating ETL transformations for each source file to bring data from CSV to Stage Table load, Stage to DQ stage and DQ stage to Data Store will be a time-consuming activity in terms of development and testing.
The efforts and estimation would be very high too. More over the ETL pattern will be repetitive as the source will be CSV files. If we follow the traditional ETL approach, we will end up creating more than 1000 transformations to bring all the data sources till Data Store layer. Maintaining and managing these many ETLs are also difficult. So we need a solution that creates a parameterized ETL or Template that accepts meta data (source and Target) information whose behavior can be changed during run-time
Solution
The solution identified is to create an ETL framework using Pentaho that has Metadata ingestion method. This approach will allow you to create parameterized ETL transformations that can change the behavior during run time. So instead of creating individual ETL transformations for each source entity (CSV files) , we can create a template transformation for a specific functionality (for e.g CSV to Table data load) and ingest meta data information to this template from property files or Database tables.
Advantages
- With Metadata Ingestion, developer agility and productivity are enhanced
- Instead of creating and maintaining dozens of transformations built with a common pattern, developers define a single transformation template and change its run time behavior by gathering and injecting meta data from property files or database tables
- ETL changes will be very minimal and we may need to change only the Meta data information if there is any change in the source. For e.g, additional columns, Data type changes, removing columns etc
