
Optimizing Performance During Data Loading and Bex Query Execution in SAP BW4HANA
Welcome to our blog where we delve into strategies for optimizing performance during data loading and query execution in SAP BW4HANA. These techniques are crucial for ensuring efficient processing and responsiveness within your SAP environment. Let’s explore some key tips and best practices.
Performance optimization during data loading:
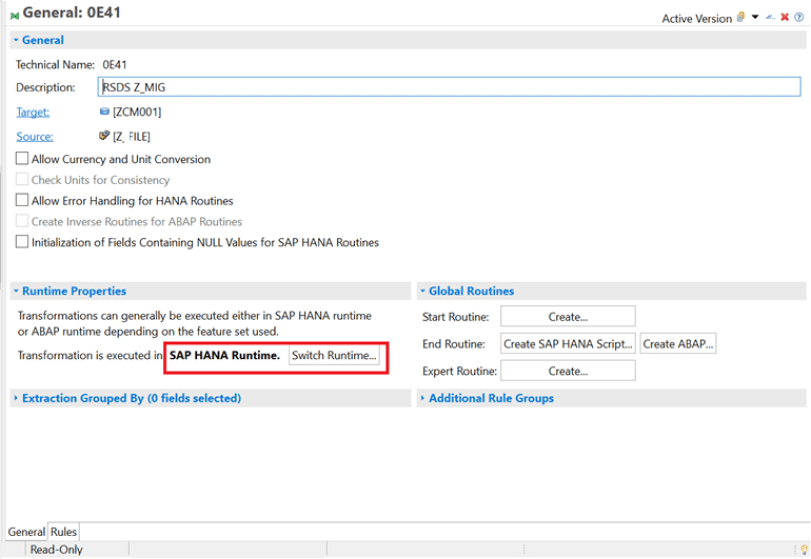
1. There are two options to process the data during the SAP transformation created between source and target providers.
1. SAP HANA Runtime
2. ABAP Runtime
HANA Runtime:
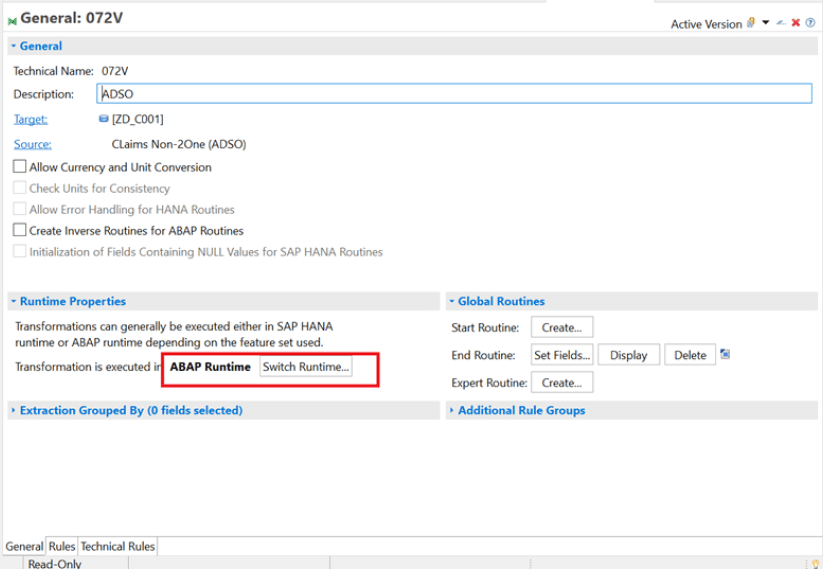
ABAP Runtime:
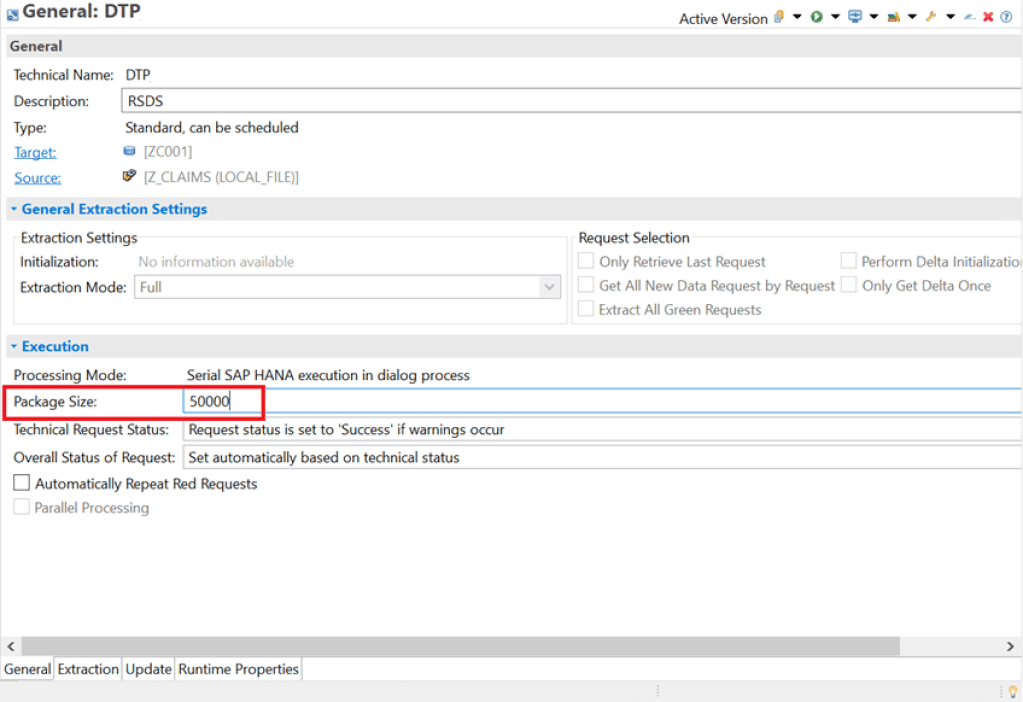
2. Split the data loads in smaller sizes by reducing the package size in DTP and by grouping the dataset by setting Semantic Grouping
DTP filter settings: Adjust the package size depending on the data size in source.
ABAP Runtime:
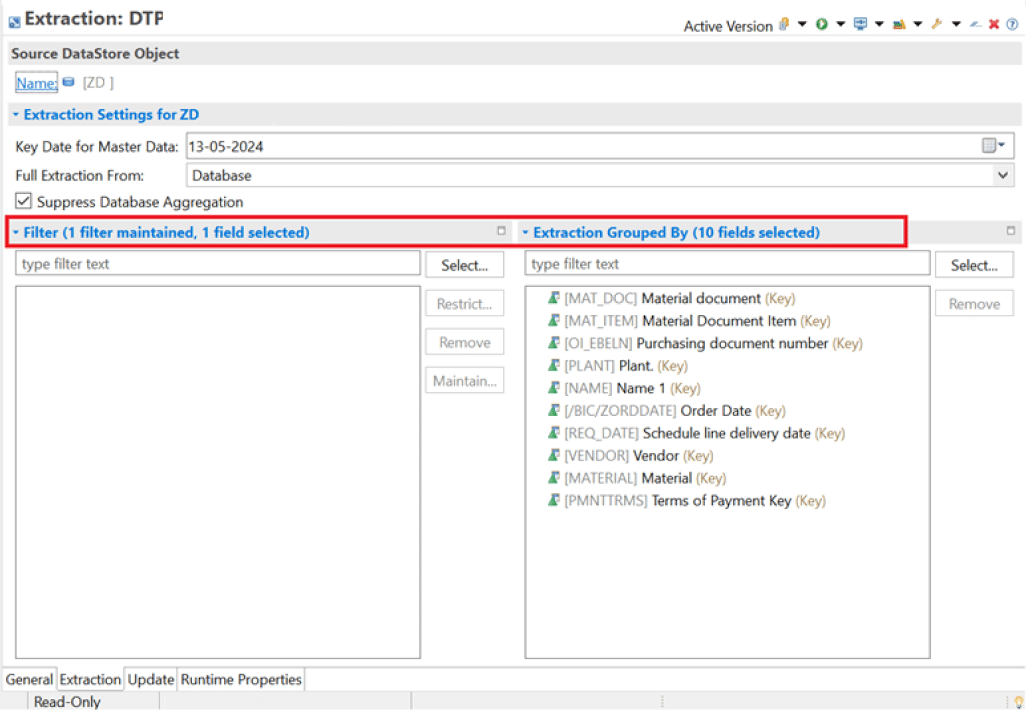
In the Extractions tab of the DTP maintenance 🡪 Filter the data in the DTP extractions to process only the required data set in the “Filter” section of the DTP and semantic grouping can by set in the “Extraction Grouped By” inorder to group the data for processing in packages.
In the Extractions tab of the DTP maintenance 🡪 Filter the data in the DTP extractions to process only the required data set in the “Filter” section of the DTP and semantic grouping can by set in the “Extraction Grouped By” inorder to group the data for processing in packages.
Performance optimization of
Bex Queries
1. Filter out data as much as possible in the initial run of the queries by adding filters or input variables based on business requirements.
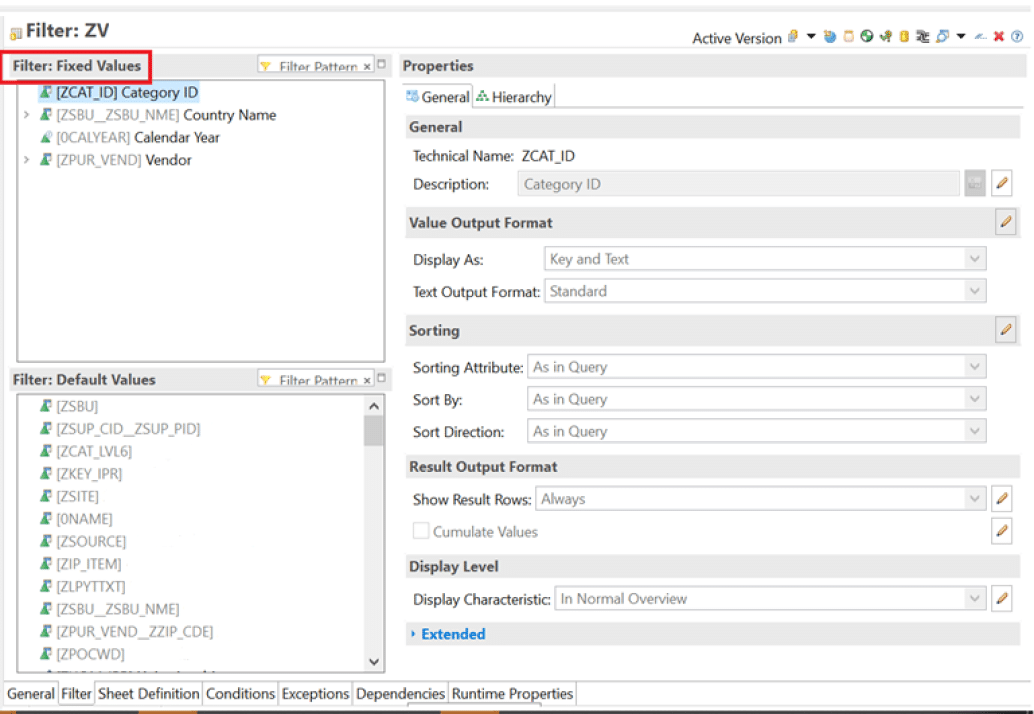
2. Queries should be generally created on top of the Composite providers than individual infoproviders like ADSOs, Infoobjects, etc. for better performance.
3. Keep only the required characteristics in the report instead of placing the entire list in the free characteristics.
4. Active hierarchies for any master data objects can be enabled after initial query run while navigating through the report which will avoid the hierarchy processing during the initial run itself thereby increasing the performance.
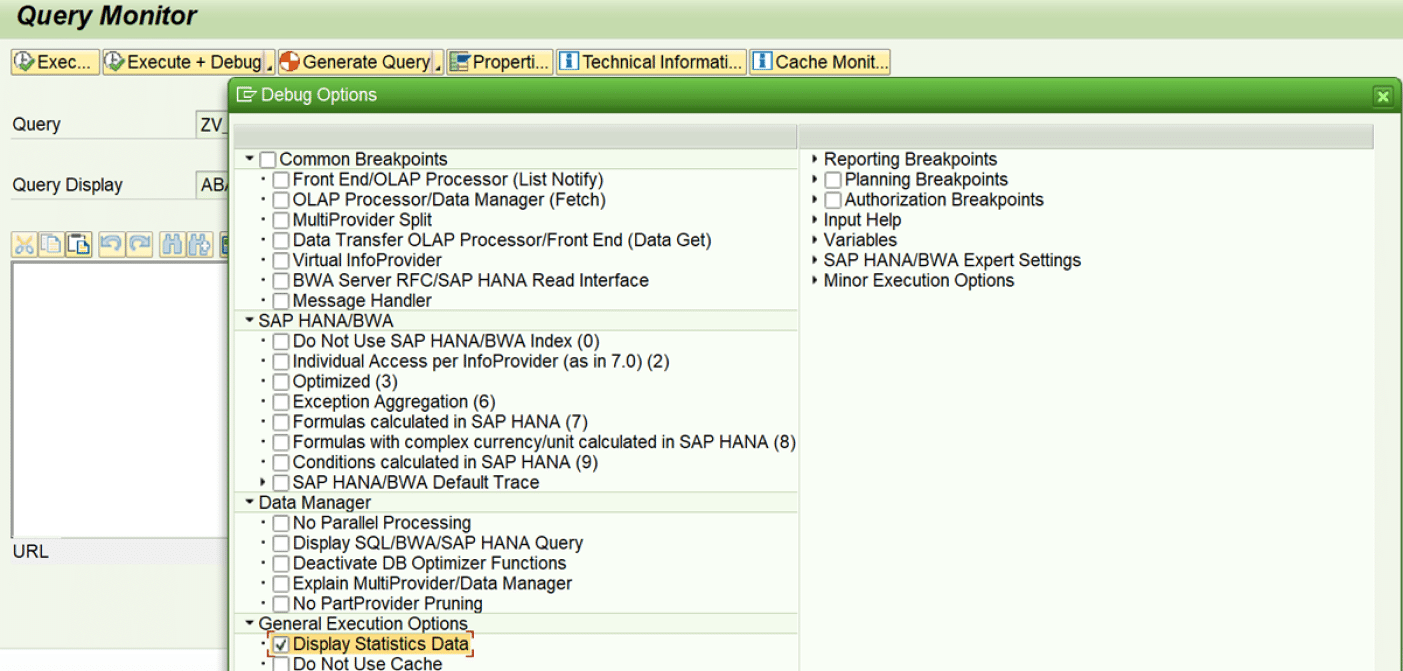
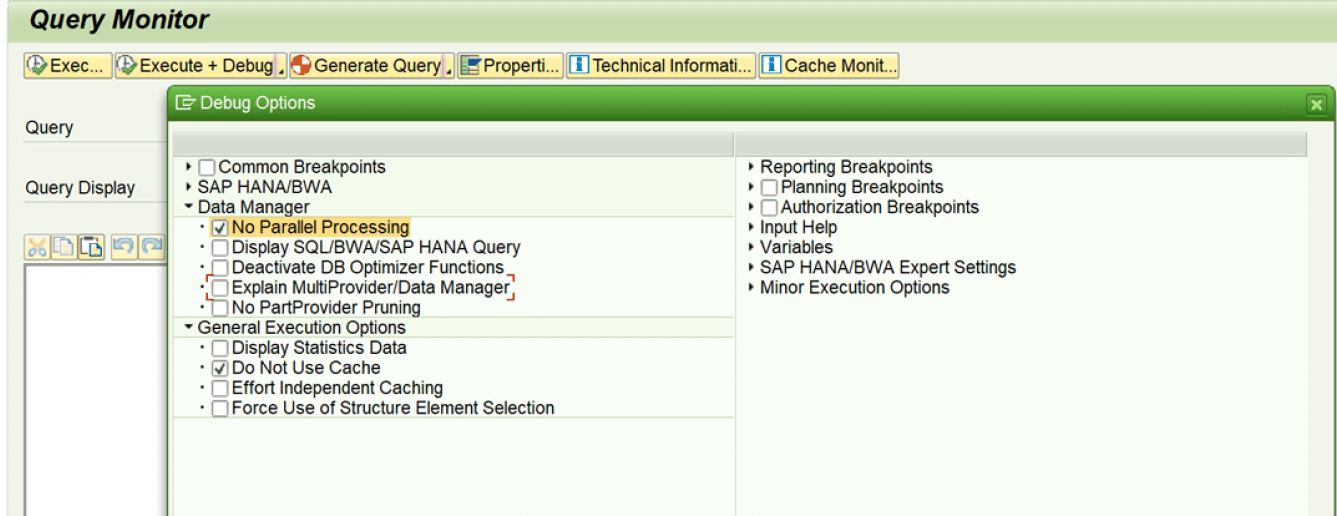
5. For detailed analysis of the query performance, we can execute the query in RSRT 🡪 Execute + Debug option 🡪 select – Display statistics data 🡪 This will display the detailed analysis of the query run.
6. Push the complex calculations to the transformation layer rather than calculating in the query runtime.
7. For the individual characteristics in the Query structure or free characteristics, set Result rows option to Always suppress 🡪 this will avoid calculation of key figure cumulation during report slice and dice.
8. Select proper decimal precision for key figures.
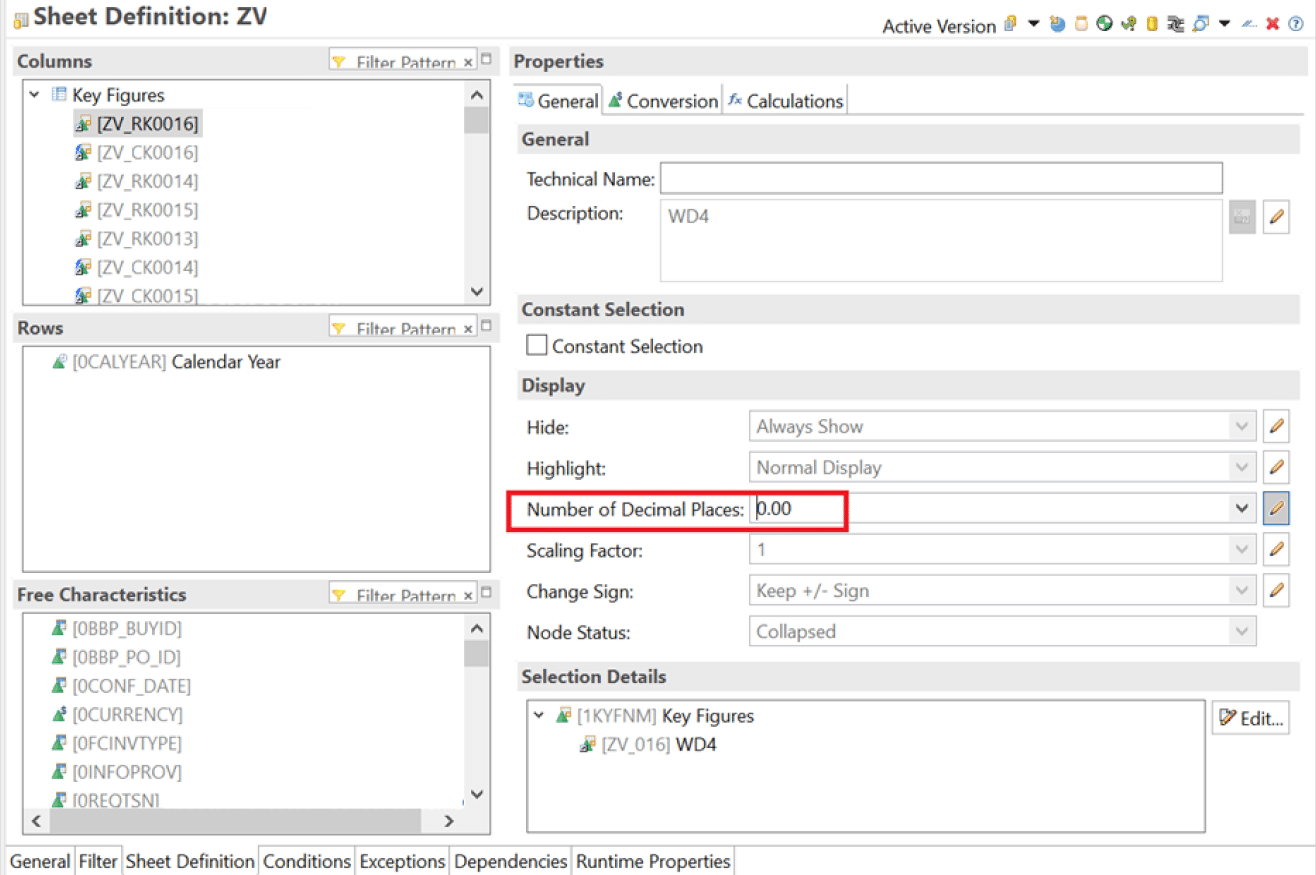
9. For queries which doesn’t have a sub query or formula variable with replacement path that executes another query 🡪 deactivate parallel processing (RSRT 🡪 Execute + Debug mode 🡪 Data Manager 🡪 select no parallel processing)

About the Author
Sneha Santhanakrishnan
Senior Technical Lead – Delivery
