
Near Line Storage (NLS) is a concept that describes intermediate type of data storage that represents a compromise between online and offline storage used for data archiving which is rarely used to access. The near line data is stored in compressed form with fewer backups and offers reduction in costs for the data that is accessed less frequently. Let us take a situation of a client with 50 terabytes of data in their entire data warehouse. Say client identifies that 25 terabytes of their entire data is historical and that they do not need to access this data on a daily basis. So instead of storing 25 terabytes of data on their regular database which occupies a huge amount of database space, if they can compress this data its storage space will also come down thus bringing down the cost of storage.
In this blog, I will be talking about the concept of Near Line Storage with respect to data archiving mechanism within in SAP BW using the concept of Near Line Storage mechanism on SybaseIQ. With reference to data archiving SAP has classified data into three classes viz., Hot, Warm and Cold. “Active data that has to be accessible on a permanent basis for read and write processes is referred to as ‘hot’ data. This data is stored in the main memory of the HANA DB. Warm data which is not accessed quite so often is best stored in the HANA DB file system. The final data class is the cold data, with which NLS is associated. Cold data is rarely used and for which no more updates are anticipated in BW. This data is removed in time slices to the SybaseIQ DB.”
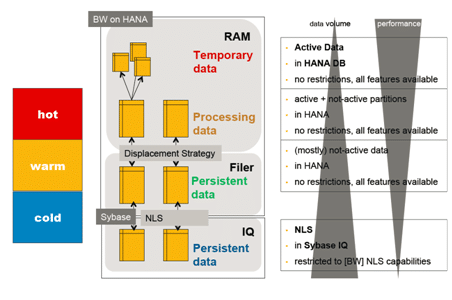
Figure 1 showing the classification of data into hot, warm and cold and how the data is stored in SAP BW. (Source: SAP Netweaver BW Near Line Solution (NLS) based on SybaseIQ, Michaela Pastor, April 4, 2013 http://scn.sap.com/docs/DOC-39944 )
NLS allows SQL-based direct access for reporting and ETL and extracted NLS partitions are deleted in RDBMS after archiving. The primary criteria of partitioning data in NLS is by time/age. The compression rate of data using NLS is upto 90% and it can handle large data volumes with minimal administrative effort. This type of archiving is very much suitable for ad-hoc queries with long history.
Certain key facts about NLS interface are:
- NLS should be part of a data-aging strategy
- Data consistency guaranteed before deleting the data from source
- Data archived in NLS can be incorporated into reporting
- Saves storage costs and other system resources
- High compression rate up to 90% (not on top of HANA compression)
- Increases retention period for analysis data
- Included in the query statistic data collection (RSRT)
- Supports archiving of InfoCubes and DataStore Objects
- Mainly time-based archiving, but can also be based on other characteristics
- Lock of the archived time slices in the original InfoProvider
- NLS process steps in process chain handling
- Copes with changes in the metadata to the BW objects of the archived data
- Deletion of NLS partitions supported
- Direct load from ADK archive files into NLS supported
A NearLine Storage acts as an intermediate solution between a traditional archiving and an online database. UsingNearLine Storage would allow us to have access to the archived data without the need of reloading the data to online database.
